
Web Scraping – что это такое и с чем его едят?

Web Scraping – это популярный метод получения контента практически даром. У нас такой метод называется «парсинг контента» или «парсинг сайтов». Метод состоит в том, что специально обученный алгоритм заходит на главную страницу сайта и начинает переходить по всем внутренним ссылкам, тщательно собирая внутренности указанных вами div-ов. В качестве результата работы – готовый CSV файл, в котором вся нужная информация лежит в строгом порядке.
Зачем?
Полученный CSV можно использовать для последующей генерации почти уникального контента. Да и в целом, как таблица, такие данные представляют большую ценность. Представьте, что весь ассортимент какого-то строительного магазина представлен в таблице, притом для каждого изделия, для каждого подвида и марки изделия заполнены все поля и характеристики. Если наполнением интернет-магазина занимается копирайтер, то он будет счастлив иметь такой CSV файл, и вы можете увидеть на его глазах слезы благодарности. Если созданием контента занимается бездушный алгоритм и душевным именем «Нина», то тексты приобретут осмысленность, пользу и, конечно же, силу земли.
Какие кнопки жать?
Инструментов, на самом деле, море, и попробовать все нет ни возможности, ни желания. В нашей команде мы благополучно пользуемся ScrapingHub. Давайте-ка посмотрим, как именно мы это делаем.
Вначале логинимся или регистрируемся:
После этого появляется идиотичный аватар, который просит вас ввести какие-то данные. Забиваем на это дело и судорожно жмем Next:
Затем вы попадаете в личный кабинет. Здесь вам необходимо создать новый проект – вот так:
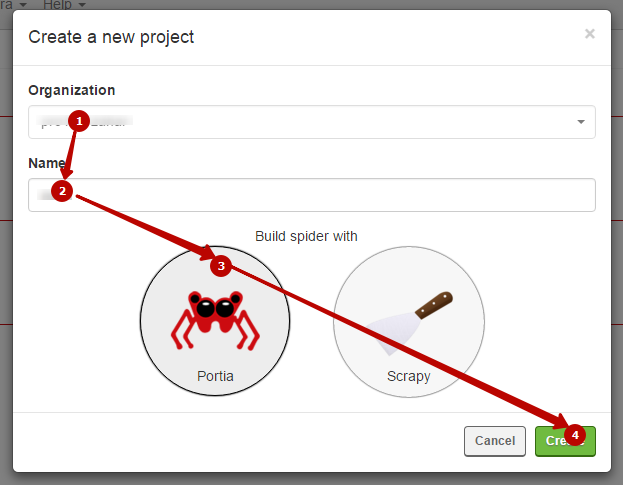
Здесь вам нужно выбрать алгоритм (будем рассматривать алгоритм Portia), а также дать имя проекту. Назовем его как-нибудь необычно. Например, «111».
Все, попадаем в рабочее пространство алгоритма, где уже нужно вводить сайт, который мы будем парсить. Нажимаем «New Spider».

Затем переходим на страницу, которая будет являться примером. В хедере обновится адрес. Жмем Annotate This Page.

Ведем курсор мыши вправо, после чего появляется меню. Здесь нас интересует вкладка «Extracted item», где нужно нажать «Edit Items».
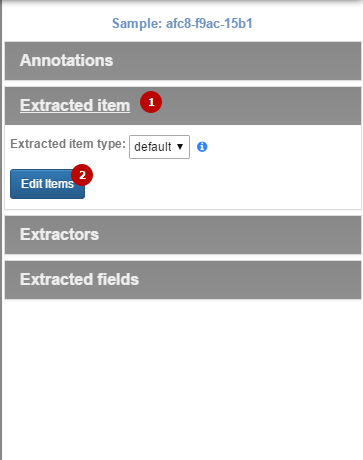
Отображается пока пустой список наших полей. Жмем «+Field».
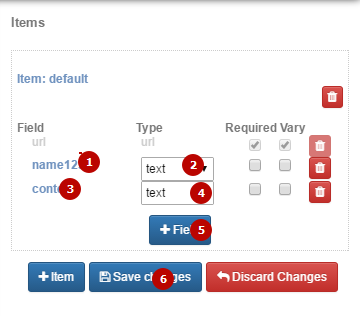
Здесь все просто: необходимо создать список полей. Для каждого item нужно ввести имя (в нашем случае, это заголовок и контент», указать, является ли это поле обязательным («Required») и может ли оно изменяться («Vary»). Если вы указываете, что какой-то Item является обязательным, то парсер будет просто пропускать страницы, где не сможет заполнить это поле. Если галочку не ставить, то парсинг может длиться бесконечно долго. Жмем Save Changes.
Теперь тупо мышкой щелкаем по нужному нам полю и указываем, что это такое:
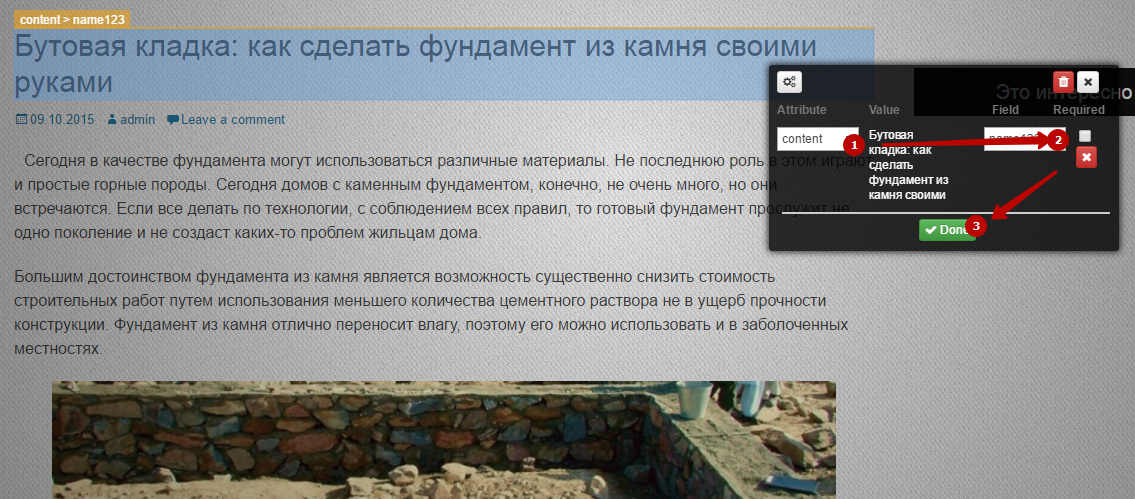
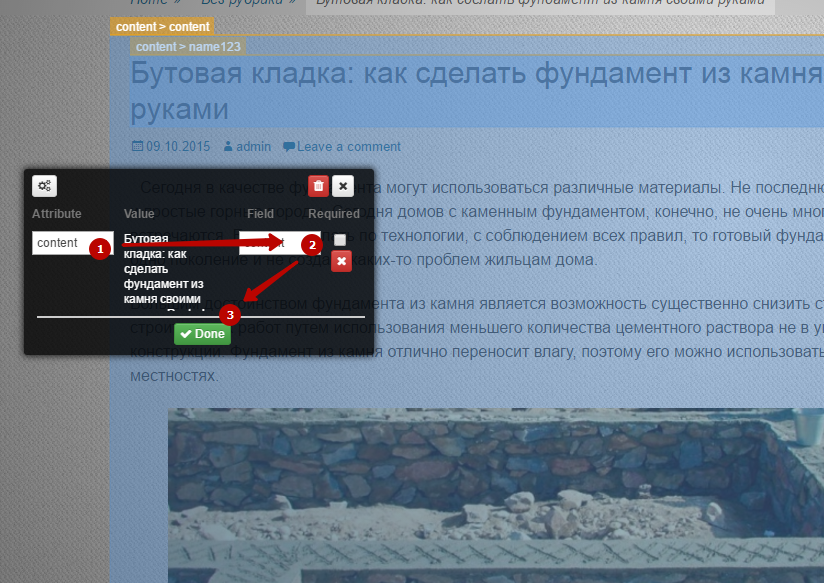
Все указали? Тогда в шапке сайта жмем «Save Sample». После этого можете возвращаться в рабочий кабинет. Теперь парсер умеет что-то доставать, нужно поставить ему задачу. Для этого нажимаем “Publish Changes”.
Переходим к доске с заданиями. Жмем “Run Spider”. Выбираем сайт и приоритет. Пуск! Ой… то есть RUN! RUN, FOREST, RUN!
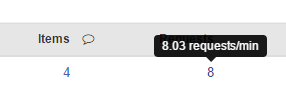
Ну, собственно, парсинг пошел. На бесплатных версиях идет он долго: около 10-50 запросов в минуту, в зависимости от скорости сервера, погоды и знака зодиака, в котором сейчас находится Меркурий. Скорость парсинга показывается по наведению на количество отправленных запросов:
Скорость получения готовых строк в CSV – по наведению на другое число.
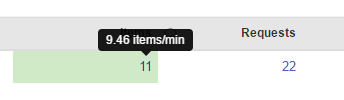
Чтобы увидеть список уже сделанных Items – просто щелкните по этому числу. Увидите что-то подобное:
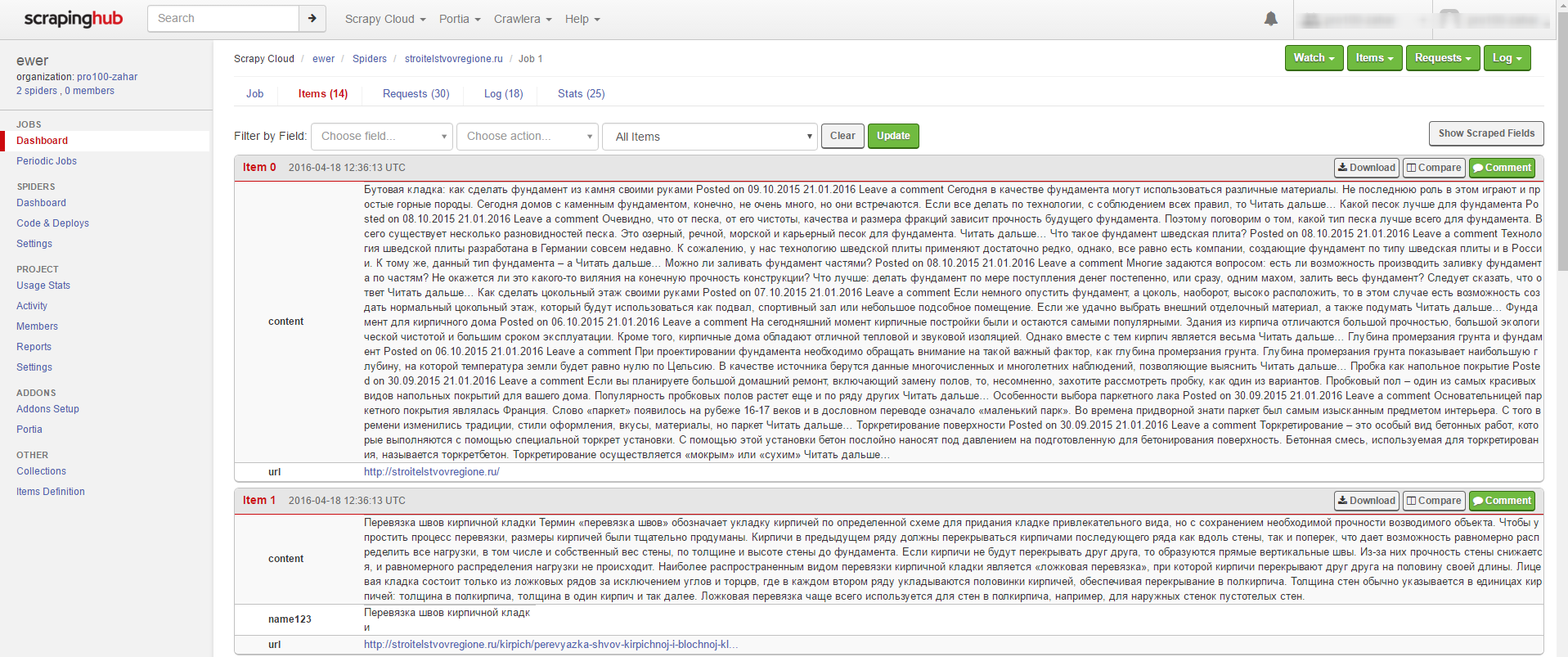
Когда парсинг закончится, результат можно сохранить вот по этой кнопке:
Как видите, здесь есть все, что может понадобиться начинающему специалисту в области парсинга.
На этом лекция окончена. Домашнего задания не будет. Первый ряд – вы неподражаемы. Есть вопросы?
— Простите, а как можно от этого защититься?
— Сайт WinStyle.Ru защищается от этого хитро: каждый раз при обновлении страницы все их div-ы получают новые названия (соотвественно, меняются и названия классов в CSS). Этого более, чем достаточно для того, чтобы парсинг перестал иметь смысл.
— Сколько длится парсинг одного сайта?
— А сколько стоит одна таблетка? Смотря какие размеры имеет сайт, как долго сервер отвечает на запросы. На нашей практике некоторые сайты полностью парсились почти за неделю. Конкретно сайт "Строительные Советы" парсился 44 минуты 10 секунд, было получено 1550 записей при 1897 запросах. Такие дела.
— Как реагируют поисковики на подобного рода контент?
— Как использовать в дальнейшем полученные данные, решать вам. Готовые CSV вы можете использовать для генерации новых текстов; как уже говорилось выше, такой CSV файл будет очень полезен как копирайтеру, так и алгоритму "Нина". Можно ли вставлять такой контент целиком без обработки? Мы не знаем. Если вам удастся представить этот контент в более удобном виде, ваш сайт будет проще и комфортней для пользователя, чем источник - почему бы нет. Но мы бы на это ставку не делали. Парсенный контент - это "сырье", которое еще нужно переработать.
— Извините, но воровать контент не хорошо!..
— Иди, я тебя расцелую, мой золотой.



Комментарии
Отличная статья автору спасибо!!!!
ОтветитьДаа, жаль, что нету Portia spider больше. Может напишете статью о том какие прокси использовать вместе со скрейпинг сервисами? палить свой IP не очень хочется. Подумываю над Smartproxy.io, ибо слышал, что у них ротация неплохая, но жаль, что трафик лимитный.
Ответить"Иди, я тебя расцелую, мой золотой" Если ты - сесапильная блондинка, то уже бегу )
ОтветитьС юморцой автор)
Ответить